Intro to Systems Programming
Systems programming is the foundation of all computing. It involves creating the software that allows your computer and devices to function effectively, ensuring that hardware and software work together seamlessly. Let’s explore how different components are interconnected in this ecosystem.
1. Operating Systems and Device Drivers
At the heart of every computer is the operating system (OS), like Windows, macOS, or Linux. The OS acts as a bridge between the user applications (like web browsers or games) and the hardware of the computer (like the CPU, memory, and storage).
Device drivers are essential parts of this relationship. They are specialized software that allow the OS to communicate with hardware devices, such as printers, graphics cards, or USB devices. When an application wants to use a printer, for example, it sends a request to the OS, which then uses the appropriate driver to communicate with the printer and carry out the task. This ensures that applications can utilize hardware without needing to know the specifics of how each device operates.
2. Firmware and Hardware
Firmware is the low-level software embedded in hardware devices, such as routers, hard drives, and keyboards. It provides the necessary instructions for how the hardware operates. The firmware is closely related to device drivers; while drivers help the OS communicate with devices, firmware directly controls the device's hardware functions.
For example, a printer has firmware that manages its internal processes, while the driver acts as the translator between the OS and that firmware. This relationship allows users to perform tasks on hardware through higher-level software.
3. Database Management Systems and Hosting
Database Management Systems (DBMS) are software applications that manage databases, helping store, retrieve, and organize data. They are crucial for applications that rely on large amounts of information, such as websites or business software.
Hosting is related to DBMS because databases need a place to reside and be accessed. Hosting providers offer the infrastructure (servers and storage) necessary to run databases effectively. The DBMS interacts with the hardware through the OS, ensuring that data is stored efficiently and can be retrieved quickly.
4. Networking
All of this ties back to networking. For applications to function across the internet or local networks, they need to communicate with servers and databases. Networking software, built through systems programming, manages data transfer, security, and protocols like TCP/IP, allowing applications to send and receive information reliably.
Why This Matters
Understanding how these components are interrelated helps appreciate the complexity and importance of systems programming. It’s not just about writing code; it’s about ensuring that every layer of software and hardware works together smoothly. This coordination is essential for everything we do with technology, from browsing the web to playing games to managing large data sets.
By developing efficient systems software, programmers ensure that hardware operates correctly, applications run smoothly, and users have a seamless experience. This foundational work is what enables all the modern conveniences we rely on today.
As an exercise, we’ll dive into systems programming and implement a simple "pipe" in C, just like how Unix-based systems handle it. Think of a pipe as a way for two programs to communicate, with one sending data and the other receiving it—kind of like passing a note!
Introduction to Pipes in Systems Programming
In Linux, pipes allow us to send the output of one process directly as input to another. This is essential for creating powerful command-line operations, similar to how you might use the | operator in a terminal.
Why Pipes?
Pipes are a core part of Unix systems. They allow us to take the output of one command and use it as input for another.
This assumes that you have a Linux based OS installed.
Step 1: Open your terminal with ctrl + alt + T
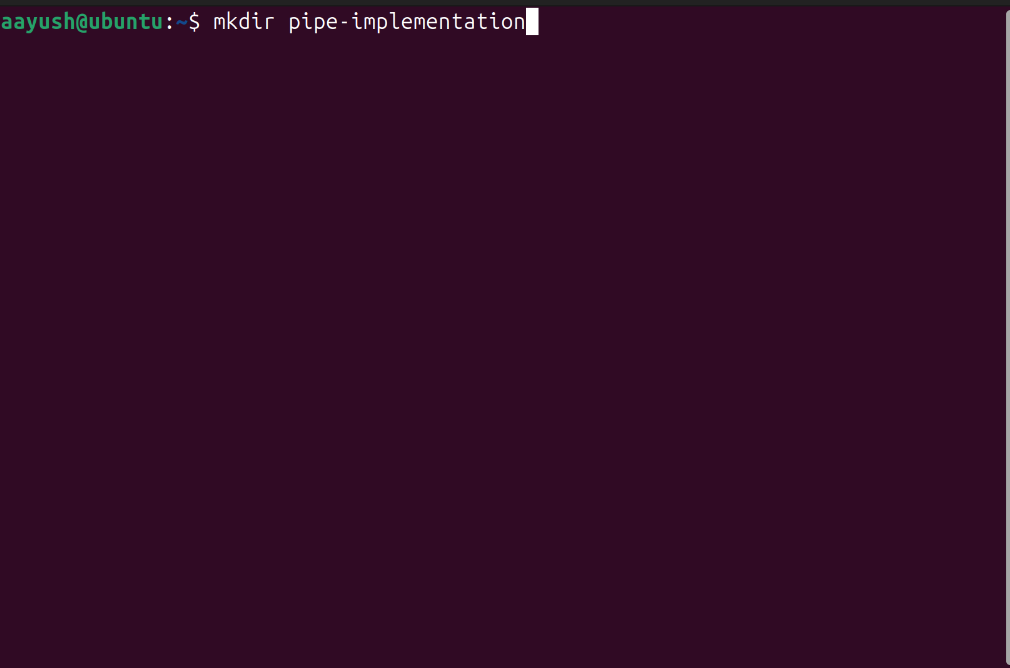
Execute $ mkdir pipe-implementation
This makes a folder called pipe-implementation where we will write our source code
Step 2: Run $ cd pipe-implementation to switch your working directory
Open a text editor in this directory, I’ll be using NeoVim but you can use anyone of your choice.
Step 3: Import all the required libraries as shown
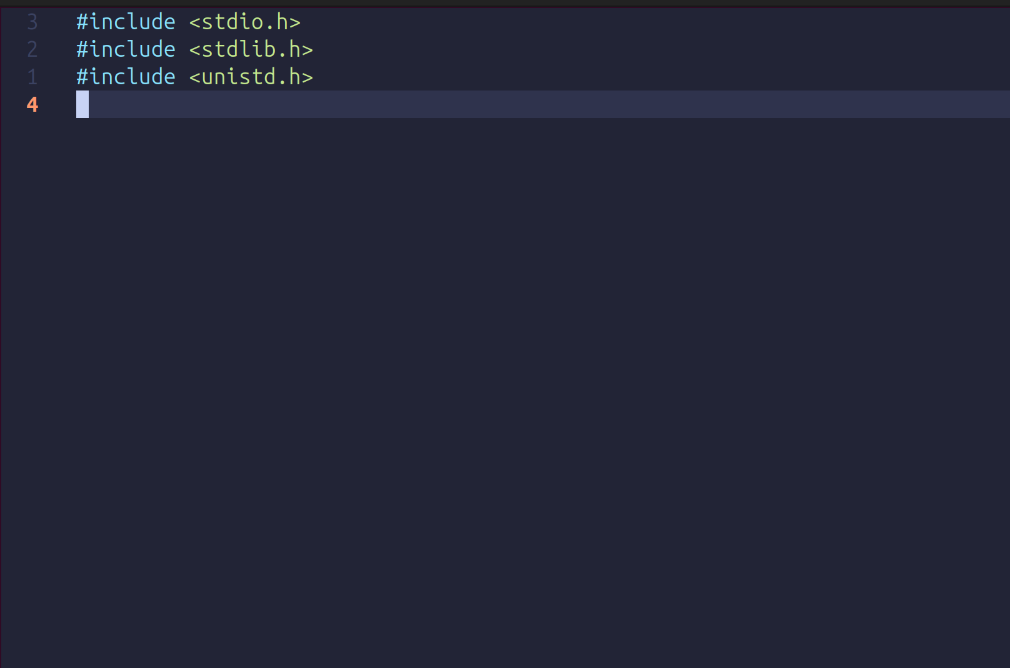
Stdio.h will be used to deal with Standard Input/Output operations
Stdlib.h will be used for process control here
Unistd.h will be used to access System calls such as pipe, fork, close etc
Step 4: In the main function write code like this, make sure to include the comment to get a nice greeting from our code later
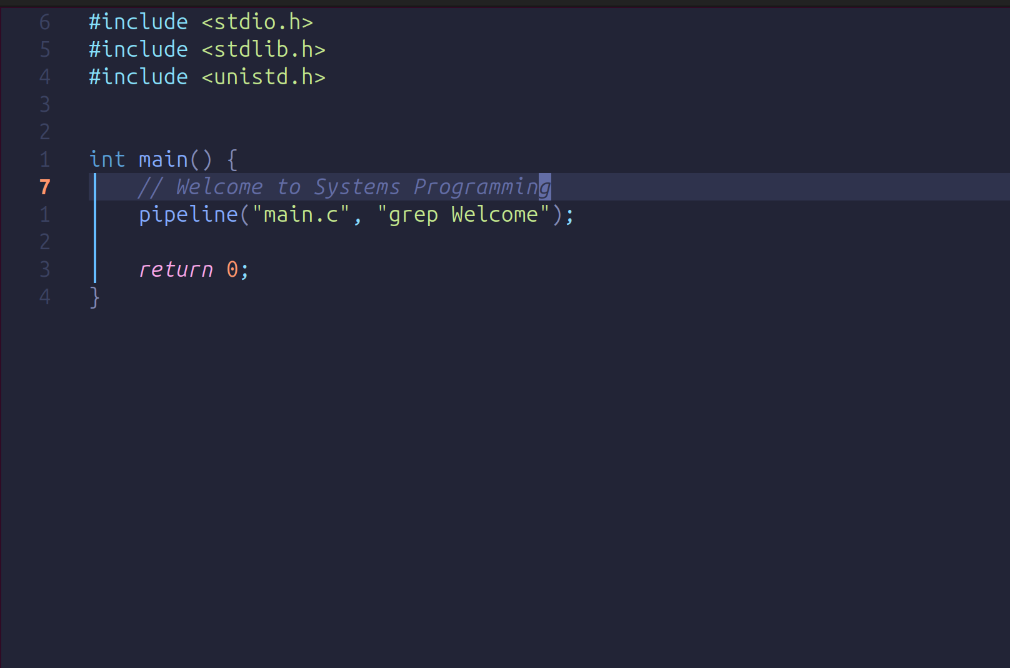
We will now define the pipeline function
Step 5:
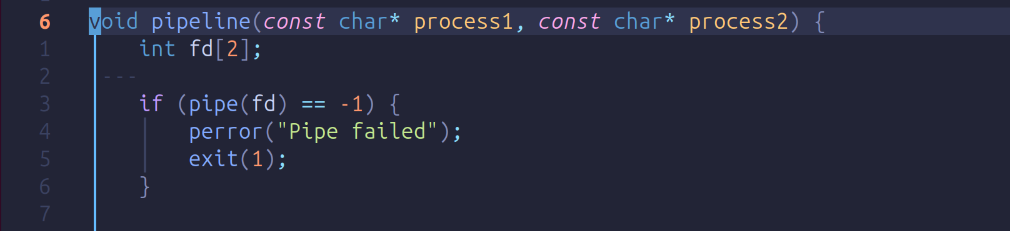
We define a pipeline function that takes two strings as input. Inside this function, we create an array called fd with size 2 to represent the read and write ends of a pipe. When we call pipe(fd), it returns -1 if there’s an error and 0 if it succeeds. If there’s an error, our code will exit the process.
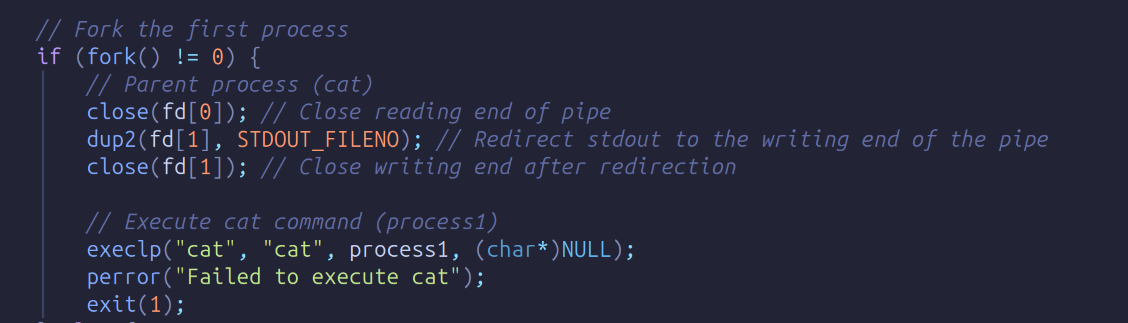
The fork() function creates a new process: the parent and the child. In the parent process, it returns a non-zero value, while the child gets a return value of 0.
Using this separation, we can run two commands at once. In the parent process, we close the reading end of a pipe because we want to write the contents of main.c to the writing end of the pipe. Then, we redirect the standard output (STDOUT) to the pipe, so instead of printing to the terminal, the output from main.c goes into the pipe for the child process to read.
Then we execute the cat command by execlp(). You need not understand everything as a beginner. This is just an exercise to introduce you to Systems Programming.

When fork() returns 0, it means we're in the child process (running grep Welcome). In the child, we close the writing end of the pipe since we don’t need to write anything. We keep the reading end open so the grep command can read the data that the parent process wrote. Next, we redirect standard input (STDIN) to the reading end of the pipe, allowing the child to read only the data from the pipe, which was provided by the parent.
Then we execute the grep command by execlp().
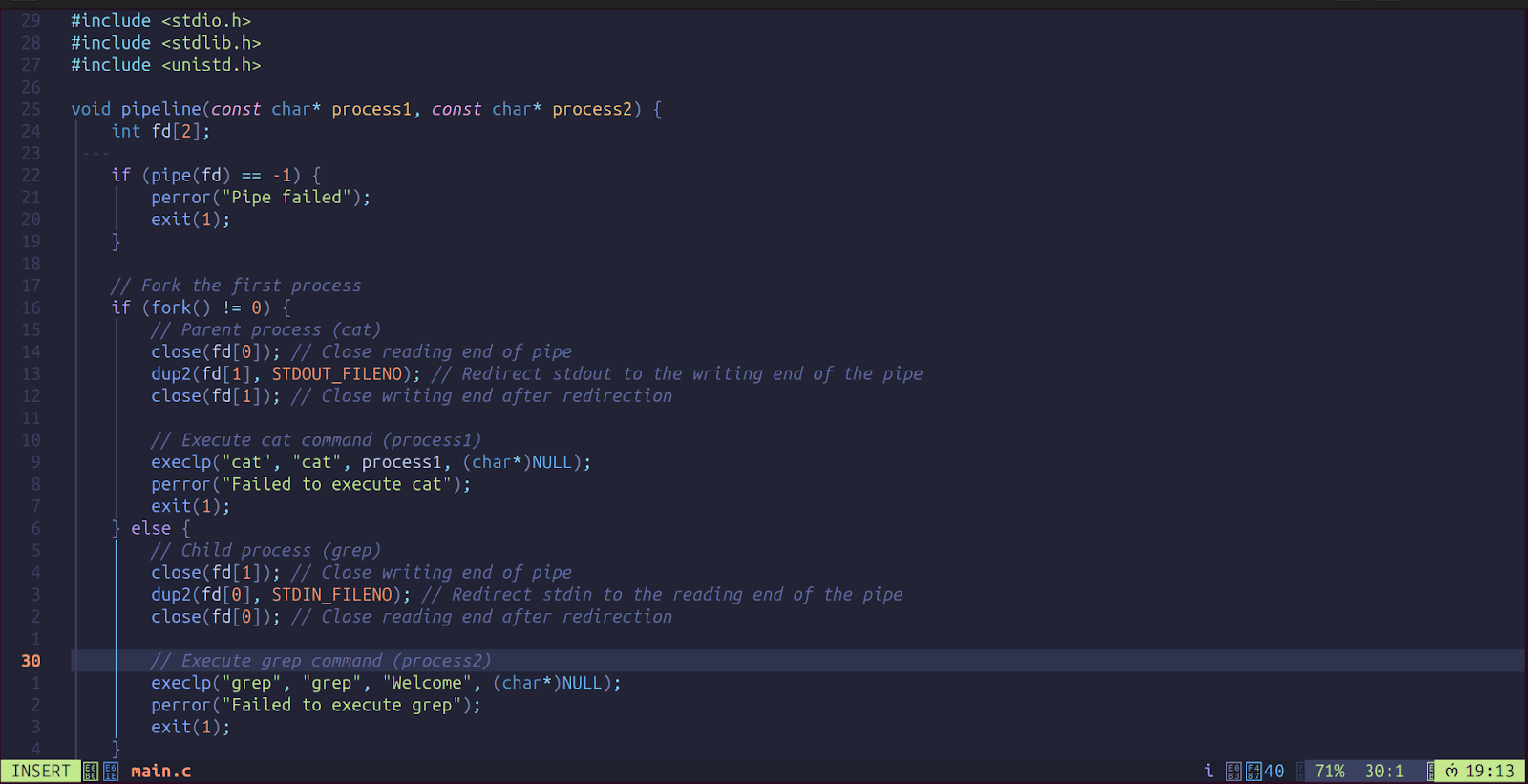
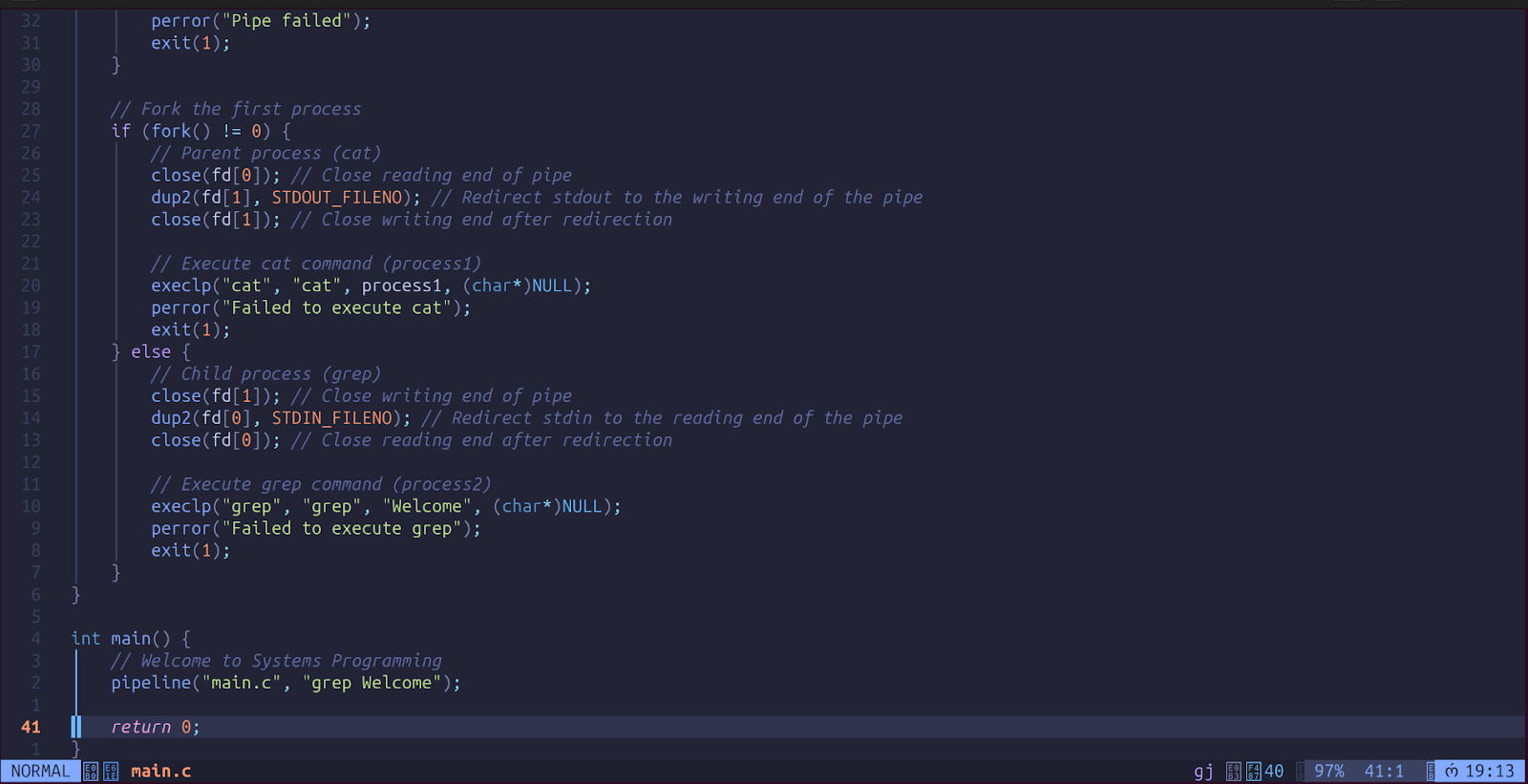
Your final code should look like this.
Step 6: Save the file and come back to the terminal in the pipe-implementation folder that we created earlier.
$ cat main.c - responsible for printing the contents of the file in the terminal
$ grep Welcome - responsible for searching for Welcome in the file
Execute the command $ cat main.c | grep Welcome
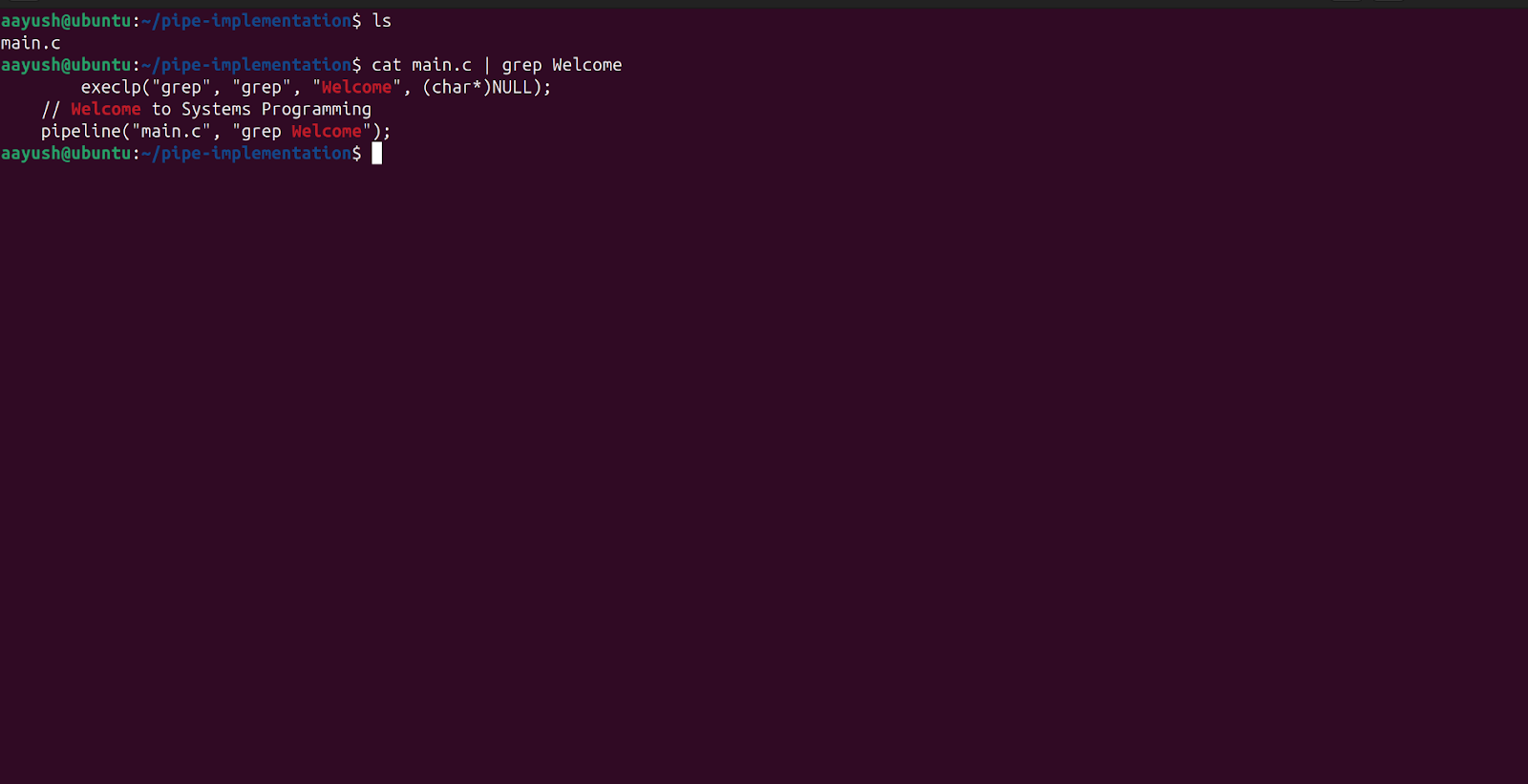
This command is supposed to print all the lines in main.c where “Welcome” is present. This is the command that we are trying to simulate through our C file
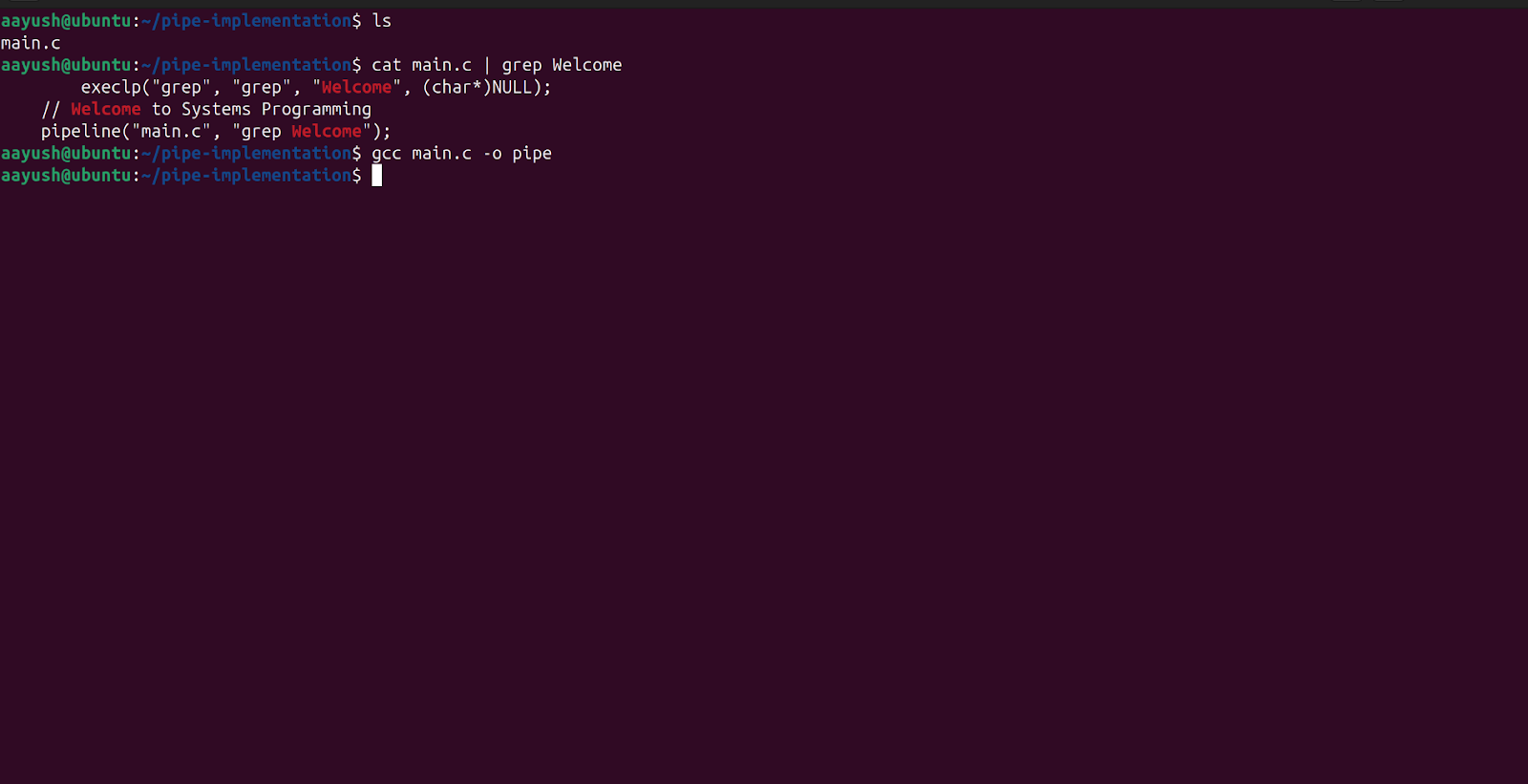
Step 7: Compile the code by: $ gcc main.c -o pipe
Step 8: Execute the code by $ ./pipe
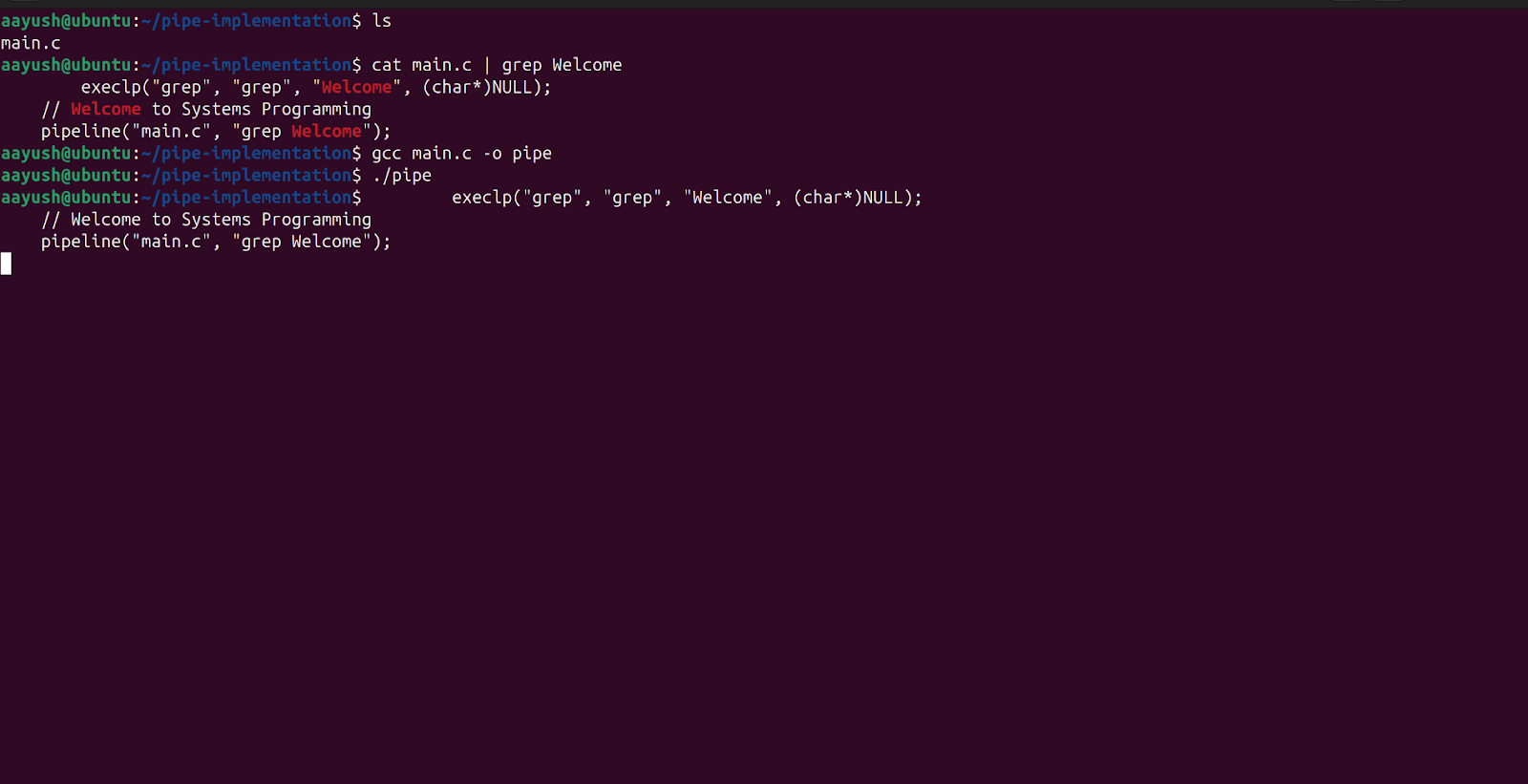
As You can see, the command that we tried earlier has been simulated!
You can find the source code for this in:
https://github.com/aayush0325/pipe-implementation
This exercise is just a glimpse into the vast and exciting world of systems programming. While this simple implementation of a pipe introduces basic concepts such as inter-process communication, process creation, and command execution, there is much more to explore.
Systems programming forms the backbone of modern computing. From writing kernel modules, managing memory, and building device drivers to optimizing performance and handling low-level networking, the field offers a wealth of opportunities to work closely with hardware, operating systems, and critical software components.
As an exercise you can try replicating a pipe with some other commands with the help of Google and flex in the COPS community group!!